I’m writing this short post to update you on a significant change in Akamai IO’s data source. Since its inception, IO’s data was based on many websites, but most of those sites catered to a US audience. This means that the data set was biased – it included global traffic, but held a disproportionate amount of traffic from the US.
Starting February 16th, we’ve started using a new data stream, based on traffic from most Akamai customers – meaning a much more global distribution, enough to take away the entire bias. The new data set is also bigger, including over a billion requests each day, and uses a newer version of our device characterization engine.
Notable Changes
Looking at the data, you can see the market share has indeed changed.
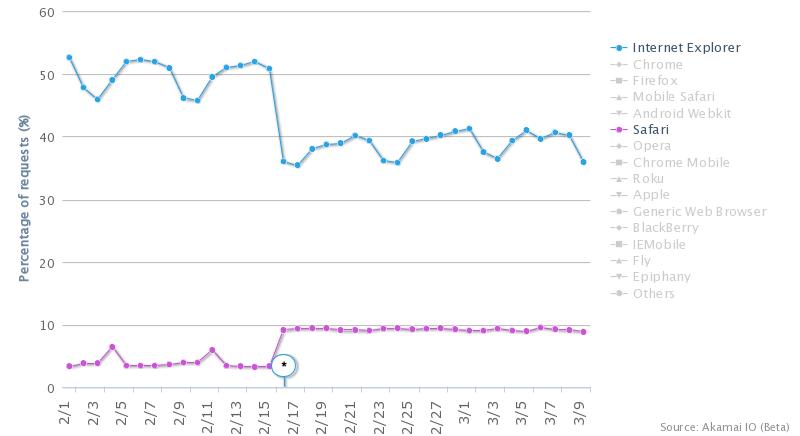
For instance, the chart below shows IE’s dominance fell from ~50% to ~40%, while Safari’s share jumped to almost 10%. My guess is that this relates to the better sample even within North America, as opposed to the theory that Safari is just more popular outside the US.
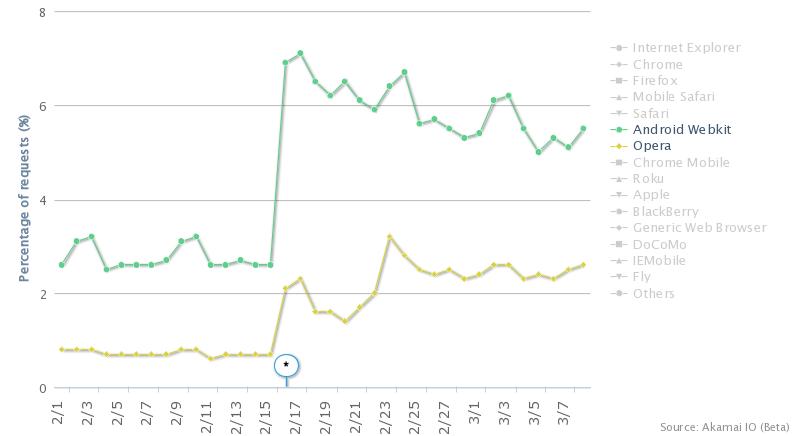
Another example is that Android’s market share increased significantly to over 5% of the overall browsing traffic, and Opera’s share more than doubled. Both browsers are known to be more popular outside the US, which is a likely explanation for this change.
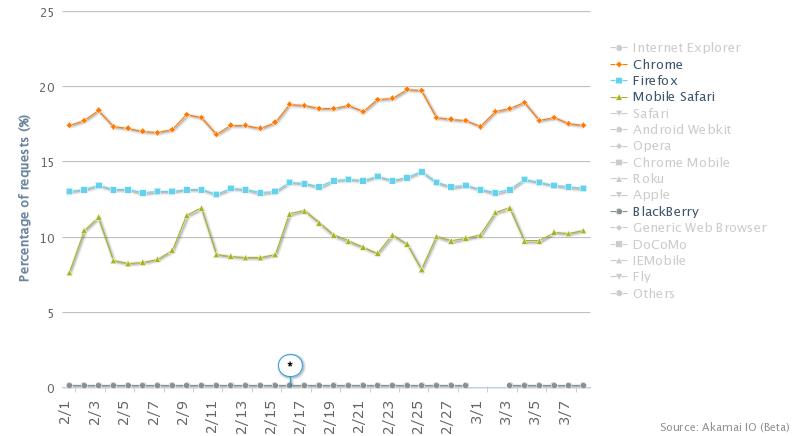
Then again, not everything changed. Chrome, Firefox and Mobile Safari maintained similar market shares, and even a global view doesn’t help make Blackberry seem more dominant…
This new global data set really highlights the need for a geographic split – showing the market shares by continent, country and perhaps even city. We’re working on this feature, along with others, and hope to have it available by May.
Some Kinks to Iron Out
Analyzing a lot of data is not as simple as summing up rows and calculating percentages. Many small details can lead to inaccuracies in the presented data, and we need to make sure we address at least the ones that matter.
For example, Akamai delivers a lot of HTTP traffic that isn’t browsing traffic. If a popular piece of windows–only software made many HTTP requests to an Akamaized domain, it may bias us to thinking windows is more popular than it really is.
Another example is wrongly identifying a device that doesn’t have a huge portion of traffic overall, but on a specific slice of the data (e.g. by geo or on cellular traffic) carries a lot of weight.
In the old data stream, we ironed out most of the big issues, but on the new stream some new ones may have surfaced. We constantly look for these changes, and try to tune the system whenever we find a flaw. If you spot something that looks wrong, please send this feedback to io@akamai.com.
Slow but Determined
It’s been almost 9 months since we launched Akamai IO at Velocity US 2012. When we did, we shared our plans to make it bigger and better over time. These ranged from getting a broader data sample, through adding more types of information, to adding APIs to access the data.
I wanted to clarify that all of these plans are still in place – we’re not moving them forward quite as fast as planned. Know that we are still committed to and investing in Akamai IO, even if we’ve been a bit slow.
Summary
The better data source we’re launching today is a good step forward. We hope you’ll find it useful, and that it will help expand our understanding of the web. You can also expect another good revision in May, and more to follow after that.
Lastly, we want your feedback!
We’ve already received a lot of feedback, and have carefully read and responded to each one – leading to our current priorities. Please keep the feedback coming by emailing io@akamai.com or through the feedback link on the portal, we truly appreciate it.